Comparative testing of GPU servers with new NVIDIA RTX30 video cards in AI / ML tasks

Reasonable price tag for GPU servers for AI / ML computing
In early September 2020, NVIDIA debuted its second generation GeForce RTX 30 family of graphics cards, the Ampere RTX architecture. NVIDIA broke with tradition when its new generations of cards were sold more expensive than their predecessors, which means that the cost of training models has remained more or less the same.
This time NVIDIA has set the price of new and more popular cards at the level of the previous generation of cards at the time of sale. For AI developers, this event is significant — in fact, the RTX 30 cards open up access to performance comparable to the Titan RTX, but with a much lighter price tag. Data science developers now have the ability to train models faster without increasing costs.
The flagship cards of the new series — GeForce RTX 3090, received 10,496 NVIDIA CUDA cores with a clock frequency of 1.44 GHz (acceleration up to 1.71 GHz), 328 third-generation tensor cores and 24 GB of 384-bit GDDR6X graphics memory. The even more affordable GeForce RTX 3080 features 8,704 CUDA cores at the same clock speeds, 272 tensor cores, and 10GB of 320-bit GDDR6X memory.
Despite the shortage of new video cards (NVIDIA has even had to apologize to the market for the resulting shortage of cards at launch), in early October the first GPU servers appeared in the product lines of hosting providers. Dutch provider HOSTKEY is one of the first European providers to test and present GPU servers based on the new GIGABYTE RTX3090 / 3080 TURBO cards. Starting October 26th, configurations based on RTX 3090 / Xeon E-2288G and RTX 3080 / AMD Ryzen 9 3900X have become available to all Hostkey customers in their data centers in the Netherlands and Moscow.
NVIDIA RTX 30: the golden middle?
The RTX3090 / 3080 cards are positioned by the manufacturer as a more productive solution to replace the RTX 20 series cards with the previous Turing architecture. And, of course, the new cards are much more efficient than the available “folk” GPU servers based on GTX1080 / GTX1080 Ti graphics cards. They are also suitable for working with neural networks and other machine learning tasks — albeit with reservations, but at the same time they are available at very “democratic” prices.
Positioned above the NVIDIA RTX 30 series are all-powerful solutions based on A100 / A40 (Ampere) cards with up to 432 third-generation tensor cores, Titan RTX / T4 (Turing) with up to 576 second-generation tensor cores, and V100 (Volta) with 640 first-generation tensor cores.
The price tag for these powerful cards, as well as for renting GPU servers with them, significantly exceeds the listings for the RTX 30, so it is especially interesting to evaluate in practice the gap in performance in AI / ML tasks.
Case Study: Face Reenactment
One of the working studies for operational testing of GPU servers based on the new RTX 3090 and RTX 3080 cards was the Face Reenactment process for the U-Net + ResNet neural network with SPADE spatially adaptive normalization and a patch discriminator. Facebook PyTorch version 1.6 with built-in Automated Mixed Precision (AMP) mode and torch.backend.cudnn.benchmark = True flag mode was used as a framework.
For comparison, the same test was run on a GPU server with a GeForce GTX 1080 Ti card, but without AMP, which would only slow down the process, as well as on a machine with a Titan RTX card.
For the sake of the purity of the experiment, it should be mentioned that in the test with the Titan RTX card, a system with an Intel Core i9–10920X processor was used, while the rest of the GPU servers with all other cards worked with a Xeon E-2288G.
Of course, it is important to compare when classifying on the same processors, since they are often the bottleneck that limits system performance. So taking the GPU test results with a grain of salt is quite appropriate in this case.
We got the following results:

The minimum difference between the RTX 3090 and the Titan RTX is particularly impressive when you consider the huge price gap between the two solutions. In the next test, the RTX 3090 deserves at least a full, deep comparison against a GPU server based on one and two RTX 2080 cards.
The lag between the RTX 3080 to the RTX 3090 is understandable given the significant difference in memory capacity — 10 GB versus 24 GB, the difference in architectures also left its mark on the corresponding two- and three-fold lag of the GTX 1080 Ti.
If you look at these results from a practical point of view in terms of assessing the financial costs of training a model in the case of renting a GPU server, then the scales finally tilt in favor of choosing a system with an RTX 3090. It is this card that will provide the best budget expenditure for both weekly and monthly tariff plans.
Hands-on research: GAN training
In the second test task, which consisted of training a Generative Adversarial Network (GAN) with the PyTorch package, it was interesting not only to compare the performance of cards of different generations, but also to track the effect of the state of the torch.backends.cudnn.benchmark flag on the final results. When training the GAN architecture, turning the flag to True gives a performance boost, but the reproducibility of the results may suffer.
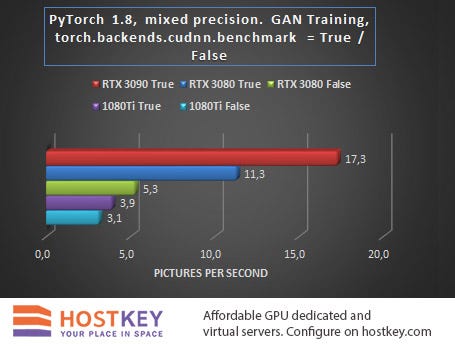
These results prove once again that the RTX 3090 card with its 24 GB of GDDR6X memory is the best choice for tackling heavy imaging tasks — both in performance (65% improvement over the RTX 3080) and in training costs when renting a GPU server.
Despite the fact that the RTX 3080 significantly outperformed the GTX 1080 Ti with any flag setting, and this despite the approximate parity in memory size, it should also be remembered that when training the GAN architecture, enabling the torch.backends.cudnn.benchmark flag = True gives a performance boost, but the reproducibility of the results may suffer. So renting a more affordable GPU server with GTX 1080 Ti cards under some conditions may be a reasonable choice, or at least comparable in budget to training models with an RTX 3080.
Unfortunately, there was no time left to run this mesh through the Titan RTX, but with a high probability the picture would remain unchanged in this case.
Hands-on research: training and inference in vision tasks
In the next test task of training networks in vision tasks, the performance of the RTX 3090 and RTX 3080 video cards was compared with the capabilities of the most powerful (and still very expensive) “veteran” Tesla V100 with 16 GB of HBM2 memory.
The tests were run using the latest version of the NVIDIA PyTorch framework (20.09-py3 from October 24th). Unfortunately, this version is not compiled for the Ampere architecture, so to fully support RTX 30 video cards, I had to use the PyTorch nightly build version, namely 1.8.0.dev20201017 + cu110. The RTX 30 series also has some problems with torch.jit, but the issue is completely removed when building PyTorch for a specific card.
In all tests, PyTorch was used with the Mixed Precision automated script, with the torch.backend.cudnn.benchmark = True flag enabled by default. Five classification models were tested for object detection with the following training settings: model forward + mean (no loss) + backward.
It is worth mentioning some of the nuances of this comparison. In particular, not the fastest V100 was used as it was working inside a virtual machine. Because of this, there could be some losses that, quite possibly, could be optimized with a better setting. In addition, all available VRAM was not involved in the testing process, which would allow further acceleration of the calculations.
Testing: Classification Training
The task of training complex neural network models is a core task for GPU servers based on NVIDIA cards, sometimes enabling the reduction of the training time of deep learning algorithms by orders of magnitude.
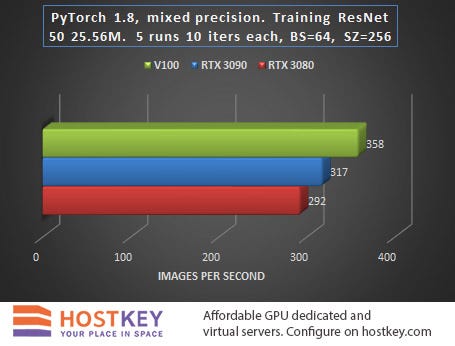
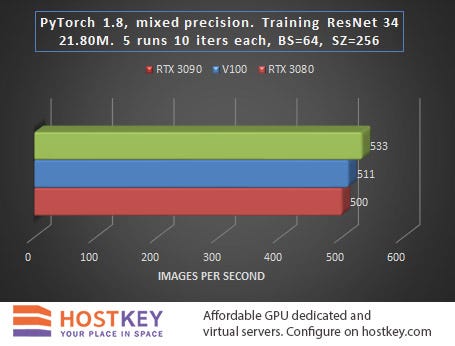
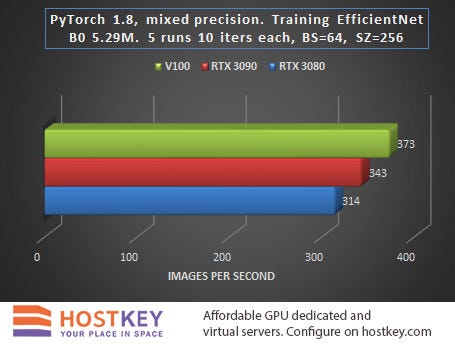
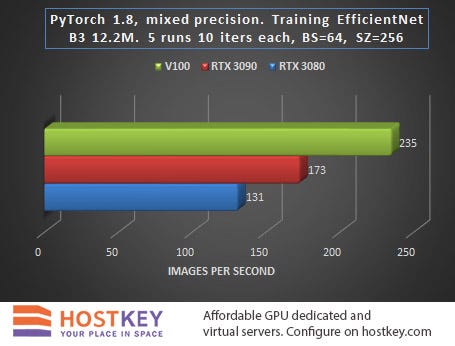
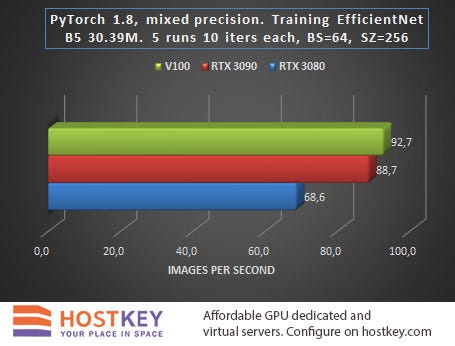
When launching the task to obtain benchmark results, the transfer of object detection was performed without an NMS, and the transfer for training did not include target matching. In other words, learning rate is likely to slow down by 10–20% in practice, and the output speed will decrease by about 20–30%.
Testing: Classification Inference
In this case, inference is the process of obtaining predictions by running images through a ready-made neural network, which is quite suitable for deployment on a remote GPU server.
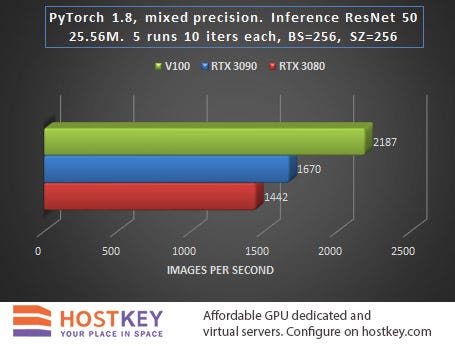
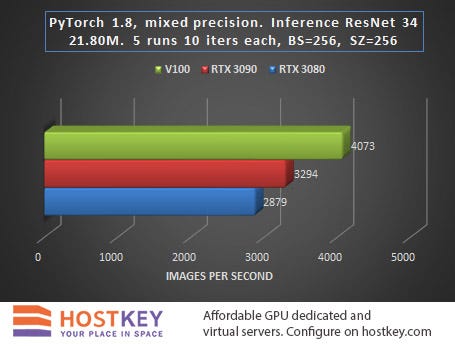
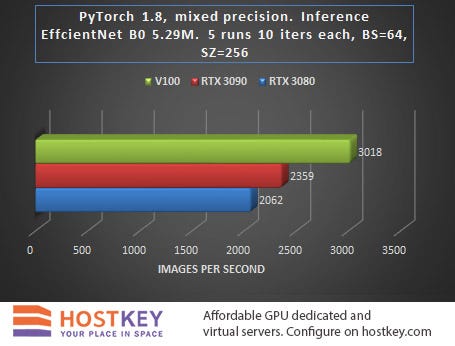
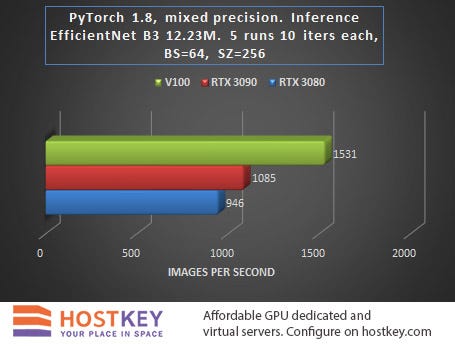
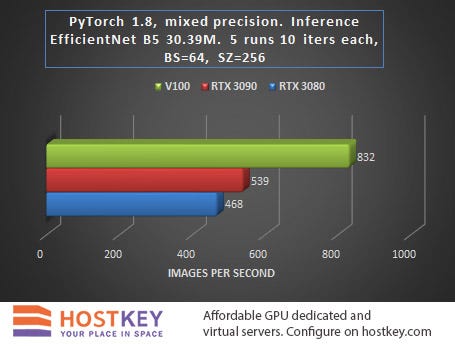
In general, we can say that in training and network inference tasks in Vision tasks, the RTX 3090 card is only 15–20% slower than the Tesla V100 on average, and this is very impressive, especially considering the difference in price.
The fact that the RTX 3080 lags behind the RTX 3090 relatively little — at least significantly less than when performing other tasks, is also indicative. In practice, this means that even with a relatively small budget allocated for renting a GPU server based on the RTX 3080, you can achieve fairly high performance with only a slight increase in data processing time.
Detection Training
RetinNet testing with ResNet50FPN for object detection was carried out with the following PyTorch parameters (20.09-py3 from October 24th), with the torch.backend.cudnn.benchmark = True flag and with model forward + mean (no loss) + backward training settings.
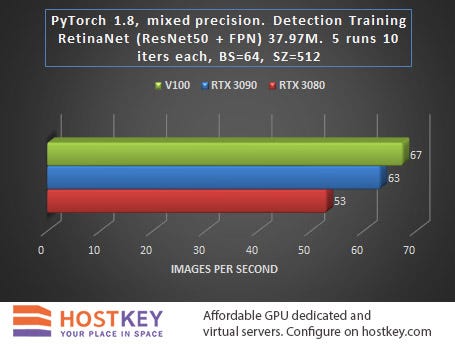
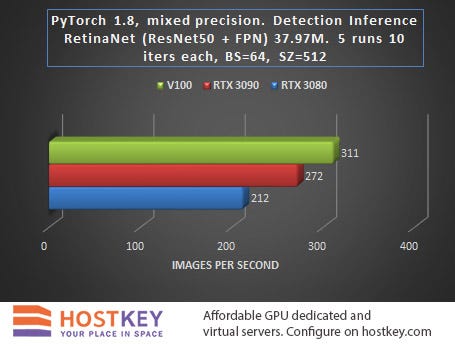
Here, the lag of RTX30 series cards is already minimal, which speaks of the undoubted advantages of the new Ampere architecture for delivering such solutions. The RTX 3090 card is, in fact, simply exceptional and has proved to be “a diamond in the rough.”
The relatively small lag of the budget card suggests that, due to its excellent price / performance ratio, the RTX 3080 should be a desirable choice for prototyping tasks on a budget. Once the prototype is complete, the model can be deployed on a larger scale, such as on GPU servers with RTX 3090 cards.
Conclusions
Based on the results of testing new graphics solutions of the GeForce RTX 30 family, we can confidently assert that NVIDIA has brilliantly coped with the task of releasing affordable graphics cards with tensor cores that are powerful enough for fast AI computing. In some network training tasks, such as working with sparse networks, the advantages of the Ampere architecture over the RTX20 generation can cut the process time in half.
The advantages of using GPU servers with GeForce RTX 3090 cards are especially obvious in tasks where model training is associated with increased memory requirements — when analyzing medical images, modern computer vision modeling, and wherever there is a need to process very large images — for example, when working with GAN architectures.
At the same time, the RTX 3080 with its 10 GB of graphics memory is quite suitable for working with deep machine learning tasks, since it is enough to reduce the size of the networks or to use smaller images in the input to learn the basics of most architectures, and then, if necessary, scale the model to the required parameters on more powerful GPU servers.
Taking into account that the HBM memory used in the A100-class cards is unlikely to become significantly cheaper in the near future, we can say that the RTX 3090 / RTX 3080 cards will be a very effective investment for the next few years.

HOSTKEY — premium web services provider in EU
HOSTKEY provides reliable and powerful GPU solutions based on NVIDIA 1080 / 1080Ti / 2080Ti / 3080 / 3090 and Tesla TESLA V100 / T4 / P100. All our infrastructure is monitored by our technicians 24/7/365. We will help you to implement the most complex solution, no matter how complex it may seem. HOSTKEY also offers grants for prospective startups and Scientific research projects.
